
목차
개요
코딩테스트를 준비하던 중 효율성 문제 때문에 HashMap을 사용해야했던 문제가 있었습니다.
풀던 중 갑자기 왜 HashMap을 사용하면 시간이 빨라질까 궁금하여 공부하게 되었습니다.
결론
결론부터 말씀드리자면 HashMap의 값을 넣는 put 메서드와 값을 가져오는 get 메서드의 시간복잡도가 O(1)이기 때문입니다. 그러면 왜 시간복잡도가 O(1)인지 파악해보도록 하겠습니다.
해시(Hash)란?
해시란 해시 함수(Hash Function)에 의해 얻어지는 값을 뜻합니다. (해시 값, 해시 코드, 해시 체크섬으로도 불립니다.)
해시 값을 전달해주는 해시 함수에 대해서도 알아보도록 하겠습니다.
해시 함수 또는 해시 알고리즘으로 불리며 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수를 뜻합니다.
이러한 해시 값을 Java의 HashMap에서 어떻게 사용하는지 파악해보고자 합니다.
Java의 HashMap 기본 원리
Java의 HashMap은 Hash Table의 자료구조 형태를 기본하여 작동합니다.
Hash Table이란 key 값을 해시 함수에 통과시킨 후, 해당 값을 인덱스로 사용한 배열에 값을 저장하는 자료구조입니다.
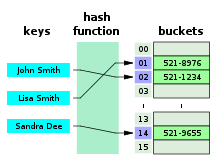
이러한 Hash Table을 바탕으로 동작하기에 값을 저장하기 위해 <Key, Value> 쌍을 전달하면 Key 값이 hash function을 통과하여 인덱스화 되고 배열의 해당 인덱스 위치에 Value가 저장되는 것입니다.
또한 값을 찾기 위해 Key값을 전달하면 hash function을 거쳐 인덱스를 얻은 후 값이 저장된 배열의 해당 인덱스 위치에 값을 얻어오면 되기 때문에 빠른 것입니다.
Java라는 Key 값에 Spring이라는 Value를 가지도록 HashMap에 저장하는 예시를 아래에 들어보겠습니다.
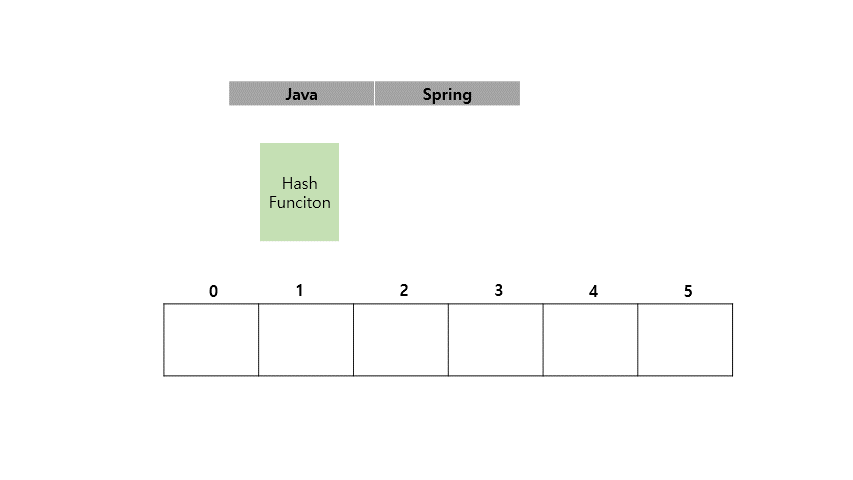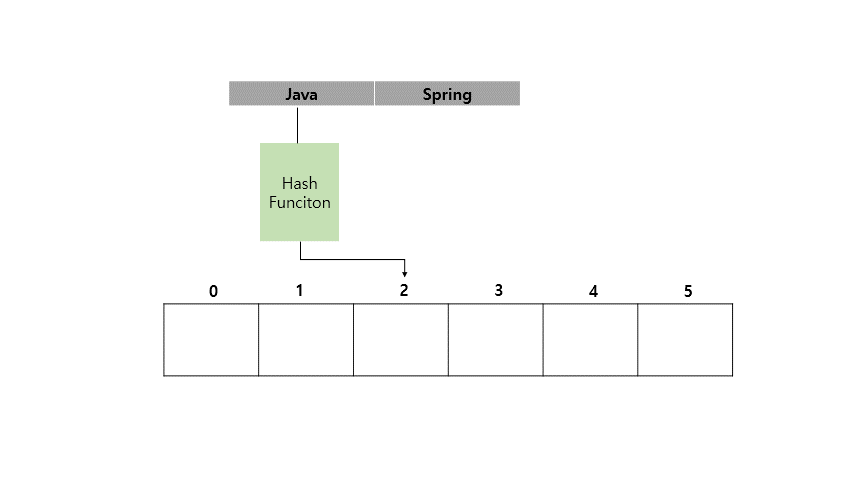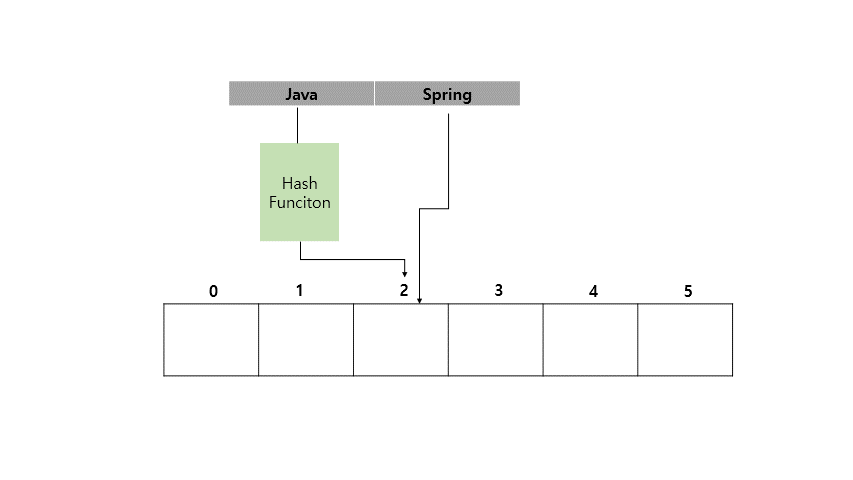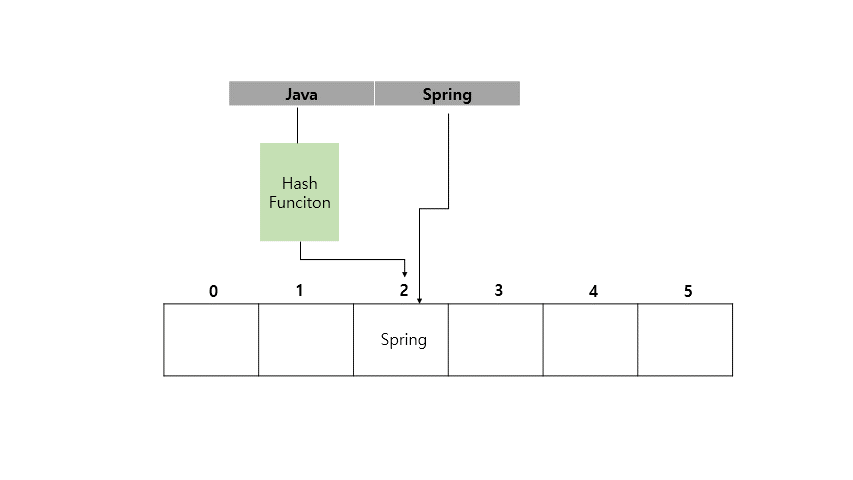
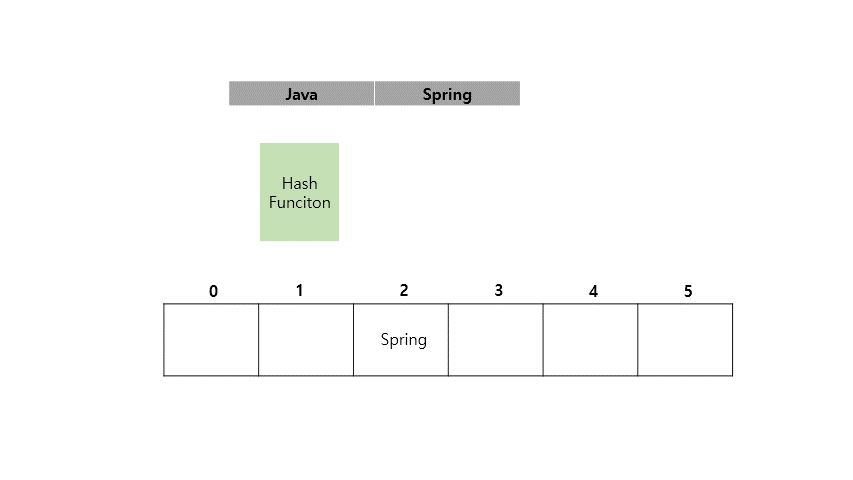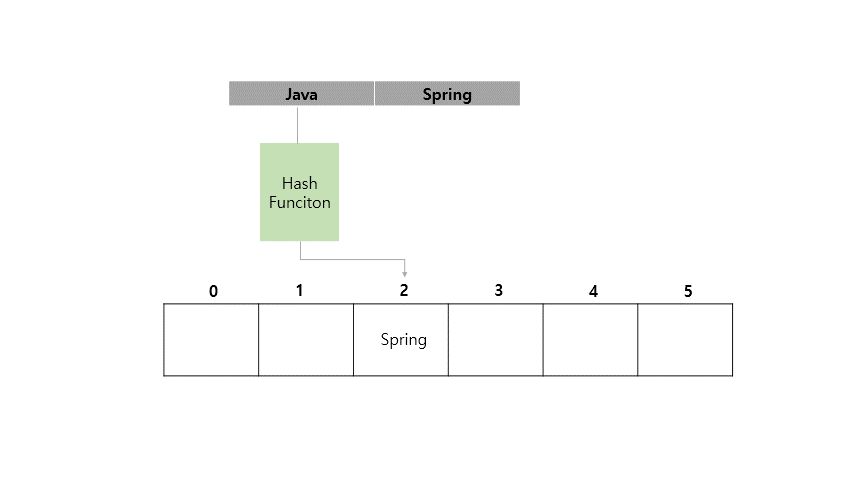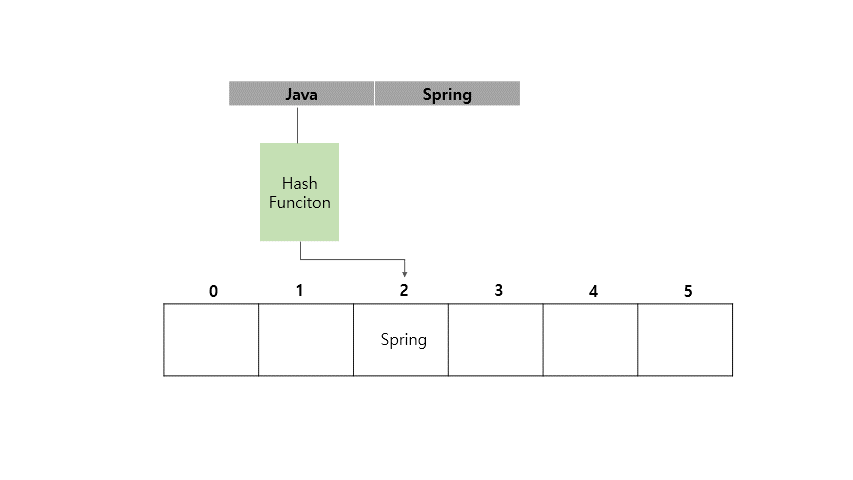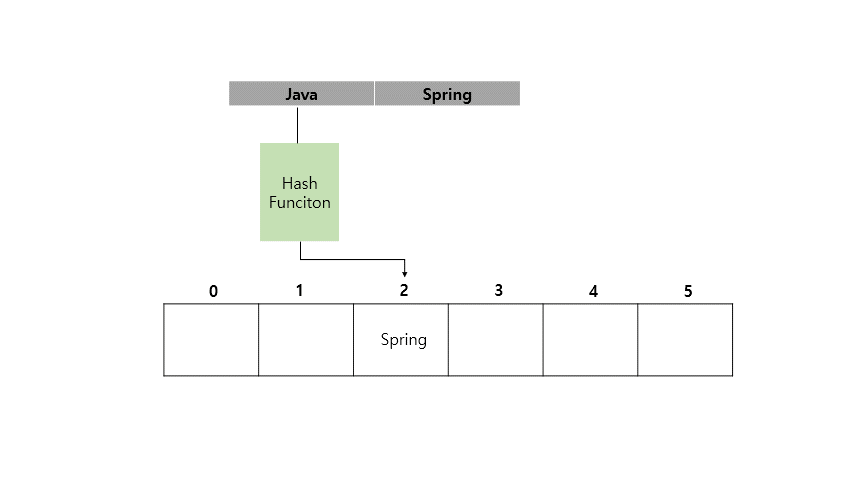
지금까지 <Key, Value> 쌍으로 이루어진 값을 Key를 인덱스화 시켜서 값을 넣고 조회하는게 빠르다는 것을 확인했습니다.
하지만 만약 새로운 <Key, Value> 쌍을 저장하려는데 새로운 Key 값의 해시 값에 이전에 저장했던 값이 있다면 어떻게 해야할까요.
해시 충돌(Hash Collision)
앞서 소개드렸던 것과 같은 이슈를 해시 충돌이라고 합니다.
해시 함수가 입력 값의 길이가 어떻든 고정된 길이의 값을 출력하기 때문에 입력값이 다르더라도 같은 결과값이 나오는 경우가 있습니다. 그렇기 때문에 해시 충돌이 발생하는 것입니다.
(그래서 해시 충돌이 적을수록 좋은 해시 함수라고 불립니다.)
해시 충돌 회피 방법
해시 충돌이 일어나도 <Key, Value> 쌍을 안정적으로 저장하고 조회할 수 있도록 하는 방법이 두 가지가 있습니다.
1. Open Addressing
Open Addressing 방식은 해시 충돌이 발생하면 비어있는 다른 공간에 해당 자료를 삽입하는 방식입니다.
(위 그림을 예시로 들면 새로운 Key값의 해시 값이 2라서 충돌이 발생하면 3번 자리가 비어있는지 확인하고 비어있으니까 3번 자리에 값을 넣는 방식입니다.)
2. Seperate Chaining
Seperate Chaining 방식은 해시 충돌이 발생하면 해당 버킷값을 첫 부분으로 하는 LinkedList를 만들어 해결하는 방식입니다.

이 중 Java는 Seperate Chaining 방식을 사용하는데 조금 더 향상된 방법을 사용합니다.
Java의 해시 충돌 회피 방법
Java에서는 해시 충돌 회피 방법으로 앞서 말씀드렸듯이 Seperate Chaining 방식을 사용하는데요. 조금 더 향상된 방법을 사용한다고 말씀드렸습니다.
조금 더 향상된 방법이란 바로 Linked List가 아니라 Tree도 사용한다는 점입니다.
Tree를 사용하게 되면 해당 인덱스에 많은 값들이 들어가게 되었을 때, Linked List보다 조회에 있어 더 높은 효율을 보이게 됩니다.
Java의 향상된 방식을 소개드릴 때 Tree도 사용한다고 말씀드렸는데요.
그 이유는 Linked List와 Tree를 함께 사용하기 때문입니다.

위 사진과 같이 TREEIFY라는 용어를 토대로 충돌이 일어난 인덱스에 값이 8개가 모이면 Linked List를 Tree로 변경하고 6개로 바뀌면 다시 Tree를 Linked List로 변경시킵니다.
이 때, 7개에 대한 기준이 없는 것을 보실 수 있는데요. 이는 잦은 Linked List와 Tree로의 변경으로 인한 성능저하를 막기 위함이라고 합니다.
정리
이렇듯 Java의 HashMap에 대한 동작 원리를 간단하게 살펴보았습니다.
사실 제가 다룬 내용은 HashMap 동작 원리의 개략적인 부분입니다.
혹시 더 많은 부분을 공부해보고 싶으신 분들께서는 아래 참조 블로그 중 네이버 d2의 글을 참고해주시기를 바랍니다.
참고 블로그
https://creampuffy.tistory.com/124
'Java' 카테고리의 다른 글
| Arrays.asList() 사용 시 주의할 점 (0) | 2025.04.03 |
|---|---|
| List에서 특정 조건 만족하는 요소 삭제하기 (List.removeIf 사용하기) (0) | 2025.01.17 |
| 상속관계의 클래스 일 때, @Builder 사용하기 (0) | 2024.11.16 |
| ObjectMapper, Pattern 등의 클래스를 싱글톤으로 사용해도 될지 고민했던 내역 (0) | 2024.11.15 |
| 인텔리제이에서 자바 버전 변경하기 (0) | 2023.10.17 |