







목차
개요
회사 코드에서 Spring Boot없는 순수 Spring으로 xml 환경 설정을 진행하고 있습니다. 이 때, 평소에 Spring Boot를 쓰던 상황에 편하게 적용하던 테스트 클래스 Component 적용을 Spring 환경에서 어떻게 진행하는지 삽질한 내용을 정리해두고자 합니다.
적용법
적용법은 하단의 블로그를 참고했습니다.
https://codevang.tistory.com/259
jUnit, Spring-Test 라이브러리 사용법
[ jUnit ] 전체 프로젝트(특히 WAS)를 구동하지 않고 단위 코드 테스트를 할 수 있게 해주는 라이브러리 [ Spring-Test ] jUnit을 확장한 스프링의 테스트 라이브러리 스프링 MVC 프로젝트를 진행할 때 코
codevang.tistory.com
테스트 폴더에 설정값을 매번 붙여넣기도 번거로울 것 같아 locations를 사용하고 file: 을 붙여주어 full-path로 입력해 실제 개발 상황에 사용 중인 설정값을 읽어오도록 하였습니다. 다만 저희는 각 상황에 따라 설정파일을 다르게 관리하고 있었기에 아래 블로그 예시와 같이 여러 파일 값을 사용하도록 하였습니다. 또한 매번 입력하는 것이 번거로울 것 같아 블로그에 소개해준 내용처럼 상위 클래스에 설정값을 넣고 상속받아 사용하는 방법을 이용하고자 합니다.
@ContextConfiguration
(locations = {"file:src/main/webapp/WEB-INF/spring/root-context.xml",
"file:src/main/webapp/WEB-INF/spring/appServlet/servlet-context.xml"})
이 방법대로 그대로 잘되었으면 좋았겠지만 2 가지 오류를 만났습니다.
Spring Bean 초기화 중 EL (Exprssion Language) 관련 종속성 누락
제가 만들어둔 설정 Bean들 중 @Valid를 사용하기 위해 만든 MehodValidationConfig 클래스가 있었습니다.
public class MethodValidationConfig {
@Bean
public MethodValidationPostProcessor methodValidationPostProcessor() {
return new MethodValidationPostProcessor();
}
@Bean
public LocalValidatorFactoryBean localValidatorFactoryBean() {
return new LocalValidatorFactoryBean();
}
}
테스트 코드 실행 시 methodValidationPostProcessor에 에러가 발생하였다고 로그가 떴었습니다.
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'methodValidationPostProcessor' defined in com.duzon.lulu.dataprotection.config.MethodValidationConfig: Invocation of init method failed; nested exception is javax.validation.ValidationException: HV000183: Unable to initialize 'javax.el.ExpressionFactory'. Check that you have the EL dependencies on the classpath, or use ParameterMessageInterpolator instead
에러 원인은 Spring에서 메서드 유효성 검증 (Bean Validation)을 수행할 때, javax.el.ExpressionFactory가 필요하지만 클래스패스에 EL 라이브러리가 없어 초기화에 실패한 것이라고 하여 아래와 같이 javax.el 라이브러리를 추가해 해결하였습니다.
<dependency>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
<version>3.0.0</version>
</dependency>
javax.el의 역할은 아래과 같다고 합니다.
javax.el.ExpressionFactory는 유효성 검증 어노테이션 내에서 사용되는 표현식을 평가하는 기능을 제공합니다. 예를 들어, @Size(min = "${minSize}", max = "${maxSize}")와 같은 유효성 표현식이 있는 경우, 이 값을 동적으로 평가하려면 javax.el 라이브러리가 필요합니다. methodValidationPostProcessor는 이러한 표현식을 처리하고 유효성을 동적으로 검증할 수 있도록 설정합니다.
회사 내부 라이브러리 Bean 생성 오류
현재 재직 중인 회사에서는 내부에서 공용 라이브러리를 사용하도록 되어 있습니다. 이 Bean들을 생성하는데 아래와 같은 오류가 발생했습니다.
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name '********': Unsatisfied dependency expressed through field '*******'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name '*******': Unsatisfied dependency expressed through field '*****'; nested exception is org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean found for dependency [javax.servlet.http.HttpServletRequest]: expected at least 1 bean which qualifies as autowire candidate. Dependency annotations: {@org.springframework.beans.factory.annotation.Autowired(required=true)}
회사 내부 코드에서는 HttpServletRequest를 Autowired해서 사용하는 경우가 꽤 있는데 이 부분 때문에 오류가 발생한 것으로 보입니다.
HttpServletRequest Bean을 자동 주입하려고 하는데 HTTP 요청을 처리할 수 있는 웹 컨텍스트가 없어서 발생하는 문제입니다. 테스트 환경에서 웹 컨텍스트를 명시적으로 설정하면 해결되는 문제라고 합니다.
@ExtendWith(SpringExtension.class)
@WebAppConfiguration
public class YourTestClass {
// Test methods here
}
각 어노테이션의 의미는 아래와 같다고 합니다.
1. @ExtendWith (SpringExtension.class)
- 역할: Spring의 테스트 컨텍스트를 JUnit 5에서 사용할 수 있게 해주는 확장 클래스입니다.
- 설명: 이 어노테이션을 통해 Spring 컨텍스트의 기본 기능을 테스트에 통합할 수 있습니다. @Autowired와 같은 의존성 주입, 트랜잭션 관리, @Transactional 테스트, 애플리케이션 컨텍스트 로딩 등을 지원합니다.
- 사용법: @ExtendWith(SpringExtension.class)는 기본적으로 모든 Spring 통합 테스트에 포함되어야 하며, Spring의 다양한 테스트 어노테이션과 함께 사용됩니다.
2. @WebAppConfiguration
- 역할: Spring MVC 테스트 시 WebApplicationContext (웹 애플리케이션 컨텍스트)를 로딩하여 웹 관련 빈들을 사용할 수 있도록 설정합니다.
- 설명: Spring MVC 애플리케이션의 웹 환경을 구성하는 WebApplicationContext를 로드하도록 Spring 테스트 컨텍스트에 지시합니다. 이를 통해 MockMvc와 같은 MVC 테스트 기능을 사용하거나 HttpServletRequest 같은 웹 관련 Bean을 사용할 수 있게 됩니다.
- 사용법: @WebAppConfiguration은 일반적으로 웹 애플리케이션 관련 Bean이 필요한 통합 테스트에 추가하며, Spring MVC 컨트롤러와 서비스 계층 간의 상호 작용을 테스트하는 데 유용합니다.
'Spring > Testing' 카테고리의 다른 글
| Spring Boot Repository Test 간단하게 실습 (0) | 2023.10.17 |
|---|
목차
개요
작업 중에 동시성 이슈에 대한 부분을 구현 할 일이 있었습니다.
시나리오는 아래와 같습니다.
- 사용자가 작업을 요청합니다.
- 사용자는 언제든 작업 취소 요청을 할 수 있습니다.
- 사용자가 작업 취소 요청을 한 경우 반드시 작업 취소가 이루어져야 합니다.
- 작업이 완료된 경우에는 특정 상태값이 업데이트 되며 상위 서비스에서 이를 파악하도록 업데이트 해줍니다.
이런 규칙 속에서 문제는 아래와 같습니다.
작업이 완료되어 상태값이 업데이트 되어야하는 순간과 작업 취소가 동시에 이루어지는 경우 입니다.
동시에 이루어질 경우 순서를 정하게 하면 아래의 두 순서가 존재할 것입니다.
작업 완료 -> 작업 취소
작업 취소 -> 작업 완료
두 순서 중 어느 것이든 간에 작업 취소가 들어왔다는 사실이 있다면 저장된 결과를 모두 날리고 초기 상태로 변경해야 한다는 사실은 변함이 없죠.
그래서 제가 생각한 로직은 아래 이미지와 같습니다.

위 로직을 통해 수행한다면 문제가 해결된다고 생각했습니다.
다만 문제는 이걸 어떻게 테스트하냐는 것이었죠.
이 과정에서 찾은 방법이 Spring 멀티스레드 동시성 테스트 였습니다.
@Test에서 멀티스레드로 동시성 테스트하기
제가 찾은 방법은 ExecutorService를 이용하는 것이었습니다.
해당 서비스를 이용하여 몇 개의 스레드를 사용할지 지정하고 수행할 동작을 지정해준 뒤 모든 스레드의 작업이 완료될 때 까지 대기 후, 결과를 보는 것이었죠. 예시는 아래와 같습니다.
@Test
void multiThreads() throws InterruptedException {
// thread 사용할 수 있는 서비스 선언, 몇 개의 스레드 사용할건지 지정
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 다른 스레드 작업 완료까지 기다리게 해주는 클래스
// 몇을 카운트할지 지정
// countDown()을 통해 0까지 세어야 await()하던 thread가 다시 실행됨
CountDownLatch latch = new CountDownLatch (2);
// thread 실행
// 보통 for문안에서 여러번 같은 코드를 실행시킴
executorService.execute(() -> {
// thread가 실행할 작업 코드 ...
// CountDownLatch의 카운트 감소
latch.countDown();
// count가 0이 될 때까지 대기
latch.await();
});
// 또는 executorService에 Runnable을 상속받은 클래스를 직접 submit할 수도 있음.
executorService.submit(new CustomRunnable());
}
해당 방법을 이용해 실제 서비스와 동일한 로직을 가진 더미 프로젝트에서 테스트한 결과를 공유합니다.
상태값은 다음과 같게 설정해보겠습니다. S(Start), I(Ing), C(Complete) 세 가지 작업 상태값을 설정하였습니다.
취소 상태값은 0 또는 1 입니다. 0이면 OFF, 1이면 ON 인 상태값인거죠.
저희의 시나리오는 상태값을 I로 설정해놓고 시작합니다. 작업이 시작되어 있는 상태라고 가정하는 것 입니다.

이후 작업 완료 기능과 작업 취소 기능을 동시에 실행하도록 설정합니다. 각 기능은 위에 설명한 이미지 로직과 동일합니다.
동시성 테스트가 실행되어 어느 로직이 먼저 실행되든간에 취소 상태값은 0으로 유지되어야하며 상태값은 S로 초기화 되어야 합니다.
테스트를 진행하면 다음과 같이 값이 바뀐 것을 확인 할 수 있습니다.

실제 테스트 코드는 아래와 같습니다.
@Test
public void tmpTest() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
CountDownLatch latch = new CountDownLatch(2);
executorService.execute(() -> {
try {
tmpService.getTmpComplete(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
latch.countDown();
});
executorService.execute(() -> {
try {
tmpService.getTmpCancelState(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
latch.countDown();
});
latch.await();
String status = tmpMapper.selectStatus(1);
assertThat(status).isEqualTo("S");
}
여러번 실행하다보면 순서가 랜덤하게 실행되는 것을 알 수 있습니다.
두 케이스에 대한 로그도 함께 첨부합니다.
(취소 먼저 실행되는 경우)
[10:39:13,272-DEBUG] org.apache.commons.dbcp.DelegatingStatement.executeQuery(DelegatingStatement.java:208)
1. SELECT 1
{executed in 1 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
[10:39:13,408-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
7. UPDATE test_row_lock
SET cancel_state = '1'
WHERE 1=1
AND id = 1
AND status NOT IN ('C')
{executed in 2 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
실패값 업데이트
기타 작업들 진행
기타 작업들 종료
[10:39:16,419-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
6. UPDATE test_row_lock
SET status = 'C'
WHERE 1=1
AND id = 1
AND cancel_state != 1
{executed in 3014 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
완료 상태값 업데이트 진행 X
진행된 작업 삭제 로직 진행
진행된 작업 삭제 로직 종료
getTmpComplete 상태값 초기화 업데이트
[10:39:21,436-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
6. UPDATE test_row_lock
SET status = 'S'
WHERE 1=1
AND id = 1
{executed in 1 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
[10:39:21,438-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
6. UPDATE test_row_lock
SET cancel_state = '0'
WHERE 1=1
AND id = 1
{executed in 1 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
기타 작업 진행
기타 작업 종료
(완료 먼저 실행되는 경우)
6. UPDATE test_row_lock
SET status = 'C'
WHERE 1=1
AND id = 1
AND cancel_state != 1
{executed in 1 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
완료값 업데이트
상위 서비스에 상태값 업데이트 전달 로직 진행
상위 서비스에 상태값 업데이트 전달 로직 종료
[11:07:16,171-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
7. UPDATE test_row_lock
SET cancel_state = '1'
WHERE 1=1
AND id = 1
AND status NOT IN ('C')
{executed in 5010 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
실패값 업데이트 X
진행된 작업 삭제 로직 진행
진행된 작업 삭제 로직 종료
getTmpCancelState 상태값 초기화 업데이트
[11:07:21,197-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
7. UPDATE test_row_lock
SET status = 'S'
WHERE 1=1
AND id = 1
{executed in 3 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
기타 작업 진행
기타 작업 종료
[11:07:24,210-DEBUG] org.apache.commons.dbcp.DelegatingPreparedStatement.execute(DelegatingPreparedStatement.java:172)
7. SELECT status
FROM test_row_lock
WHERE 1=1
AND id = 1
{executed in 1 msec} (Slf4jSpyLogDelegator.java.sqlTimingOccured():365) [jdbc.sqltiming]
[Spring Boot] @Test에서 multi thread로 동시성 테스트하기
이 글은 인프런 '재고시스템으로 알아보는 동시성이슈 해결방법' 강의를 듣고 작성한 글입니다. 테스트 작성 시 multi thread로 동시에 일어나는 일을 가정한다.멀티 스레드란?정의 : 프로세스 내에
velog.io
https://parkjeongwoong.github.io/articles/Failure/5
Java (Spring Boot) 동시성 테스트
# Java (Spring Boot) 동시성 테스트 ``` 이 글은 한옥 스테이의 예약 시스템을 만들며 마주한 동시성 문제를 해결한 과정을 다룹니다. ``` ## 서론 최근 한옥 스테이에 사용할 예약 시스템을 만들고 있
parkjeongwoong.github.io
목차
개요
현재 근무하고 있는 회사에서 MyBatis를 통해 DB와 통신 할 때, 파라미터를 HashMap으로 넘기고 있습니다. 이 경우 VO를 써야한다와 HashMap을 써야 한다에 대해서는 꽤 오래된 논의인 것으로 보입니다. 여기서는 VO를 써야한다 HashMap을 써야한다에 대한 논의는 하지 않으려고 합니다.
다만 현재 팀에서 HashMap을 파라미터로 사용하고 있을 때 겪는 문제가 있는데 이 부분을 HashMap을 쓰지 말자가 아닌 쓰더라도 오류가 있을 시 최대한 컴파일러 오류로 나타나게 하여 IDE에서 확인이 되어 배포 전에 확인 가능한 방법을 고민한 결과를 공유하고 혹시 더 좋은 아이디어가 있을지에 대해 정리하고자 합니다.
현재 회사에서 진행되는 코드 방식
현재 회사에서는 DBconnection을 만들어주는 클래스를 Mapper 클래스로 지정하고 있습니다.
Mapper 클래스에서는 회사에서 제공해주는 코드를 상속하여 DB와의 연결을 진행하는데 해당 클래스는 SqlSessionSupport를 상속받은 클래스 입니다.
xml 파일을 통해 SqlSessionFactory 빈을 설정하여 DB Connection에 대한 설정을 해주고 그를 Mapper 클래스에 주입해서 사용하게 합니다.
@Resource(name = "sqlSessionFactory")
public void setSqlSessionFactory(SqlSessionFactory sqlSession) {
super.setSqlSessionFactory(sqlSession);
}
이후에는 원하는 쿼리문을 작성한 xml 파일의 쿼리 아이디와 연결해주면 끝입니다.
예를 들어 ID로 특정 상태값을 가진 회원의 정보를 조회하는 쿼리 아이디가 selectMemberByStatus 라면 아래와 같은 메서드를 만들면 되는 것인거죠.
public HashMap<String, Object> selectMemeberByStatus(HashMap<String, Object> param) {
return selectOne("mapper.service.memberMapper.selectMemeberByStatus", param);
}정말 단순히 연결하는 것외에는 아무것도 안하는 메서드입니다.
현재 코드 방식의 문제점
위에서 안내드린 회사 코드 진행 방식으로 작업해오며 제가 겪은 문제는 크게 2가지 입니다.
1. 조회 조건에 값이 추가되는 경우 해당 메서드를 사용하는 모든 곳을 하나하나 찾아가며 수정해주어야 한다.
2. HashMap으로 만들어서 넘기는 과정에서 실수가 생기는 경우가 종종 있다.
1. 조회 조건에 값이 추가되는 경우 해당 메서드를 사용하는 모든 곳을 하나하나 찾아가며 수정해주어야 한다.
예를 들어 서비스 단에서 mapper 메서드를 사용하는 곳이 30곳이 된다고 해보죠. 이 상황에서 조회 조건이 하나, 두 가지 추가된다고 생각해봅니다. memeber를 조회 하는 상태값에 대한 정의가 추가되어 a, b가 추가되었다고 생각해보는거죠.
그러면 selectMemberByStatus를 참조하는 모든 메서드를 하나하나 찾아서 아래와 같이 코드를 변경해주어야 합니다.
new HashMap<String, Object> {{
put("기존Key", "기존Value");
put("aKey","a");
put("bKey","b");
}};IDE에서 해당 메서드를 사용한 곳을 모두 알려주겠지만 간혹 작업하다가 실수로 누락되는 케이스가 발생할 수 있습니다.
2. HashMap으로 만들어서 넘기는 과정에서 실수가 생기는 경우가 종종 있다.
위 내용에서처럼 HashMap으로 만드는 과정 중에 실수가 생기는 경우가 종종 있습니다. 예를 들어 위와 같은 HashMap을 설정해서 mapper로 넘기는데 아래와 같이 설정을 했다고 해보죠.
new HashMap<String, Object> {{
put("기존key", "기존Value");
put("aKey","a");
put("bKey","b");
}};이 경우 실제 동작 시 오류가 발생할 수 있는데 왜 발생하는지는 에러 메시지를 받기 전까지는 알기가 쉽지 않습니다. k를 대문자로 써야하는데 소문자로 써야했다는걸 IDE에서 오류로 보여주지 않는데 눈으로 발견하기는 쉽지 않습니다.
키 값을 enum으로 처리하여 받는 방법도 있겠지만 그 경우 만약 동일한 키값을 가진 서로 다른 Entity에 대해서는 어떻게 처리할지 걱정되기도 하고 그럴거면 그냥 VO를 쓰는게 낫지 않을까라는 생각을 하였습니다.
위 상황에 대해 최대한 컴파일러 오류를 내기 위한 아이디어
제가 생각한 방법은 Mapper 클래스에 값을 넘길 때, 완성된 HashMap으로 넘기는 방법이 아닌 각각의 파라미터로 넘긴 후 Mapper 클래스 메서드 내부에서 합쳐 전달하는 것 입니다. 아래의 예시처럼 말이죠!
public HashMap<String, Object> selectMemeberByStatus(long a, String b) {
HashMap<String, Object> param = new HashMap<String, Object>() {{
put("aKey", a);
put("bKey", b);
}};
return selectOne("mapper.service.memberMapper.selectMemeberByStatus", param);
}위와 같은 방식으로 진행하면 만약 파라미터를 추가해야되는 경우 아래와 같이 변경하게 될 것 입니다.
public HashMap<String, Object> selectMemeberByStatus(long a, String b, Sting c, String d) {
HashMap<String, Object> param = new HashMap<String, Object>() {{
put("aKey", a);
put("bKey", b);
put("cKey", c);
put("dKey", d);
}};
return selectOne("mapper.service.memberMapper.selectMemeberByStatus", param);
}이렇게 바뀌게 되면 기존에 selectMemberByStatus(a, b)로 사용하던 메서드들에 대해 IDE가 오류를 표시해줄 것이며 컴파일 시에도 에러가 발생할 것입니다. 그렇기에 에러가 발생하는 곳을 가서 고치면 되는 것이죠.
목차
IntelliJ에서 여러 줄 주석을 하나의 멀티 주석(/* */)으로 변환하는 직접적인 단축키는 없지만, 아래 방법을 통해 쉽게 할 수 있습니다:
- 주석 처리할 코드 블록 선택
- 마우스를 사용하거나 Shift + 방향키로 여러 줄을 선택합니다.
- 멀티라인 주석으로 변경
- 주석이 달린 코드를 선택한 상태에서 Ctrl + / (Windows/Linux) 또는 Cmd + / (macOS)을 눌러 선택한 줄에 // 단일 라인 주석을 적용하거나 해제할 수 있습니다.
- 주석을 멀티라인 주석으로 변경하려면 선택한 상태에서 Ctrl + Shift + / (Windows/Linux) 또는 Cmd + Shift + / (macOS)을 사용하면 /* */ 형태로 변환됩니다.
이 방법으로 단일 주석을 멀티 주석으로 쉽게 변환할 수 있습니다.
목차
개요
Spring에서 다중 DB를 설정하고 사용하는 법을 연습하면서 PostgreSQL은 PostgreSQL의 CLI환경에서 MariaDB는 HeidiSQL에서 따로 관리하려고했습니다. 이 과정에서 서로 다른 프로그램으로 관리하려니 불편한 점이 많았습니다. 이런 상황에서 쓸 수 있다는 DB 관리 툴인 DBeaver를 설치하고 만들어두었던 DB를 연동해보려고합니다.
DBeaver 설치
https://dbeaver.io/ 에 접속하여 Community Edition을 자신의 OS 설정에 맞게 설치합니다.

저 같은 경우에는 윈도우를 사용하므로 Windows installer를 설치하도록 하겠습니다.
설치한 파일을 실행합니다.
DBeaver에 DB 연결하기
이후에는 기본 설정으로 설치를 쭉 진행하시면 됩니다.
설치가 완료되었다면 아래와 같이 DBeaver 어플을 찾아 실행해줍니다.

실행하면 처음으로 Connection을 만들기 위해 데이터베이스를 선택하라고 뜹니다.
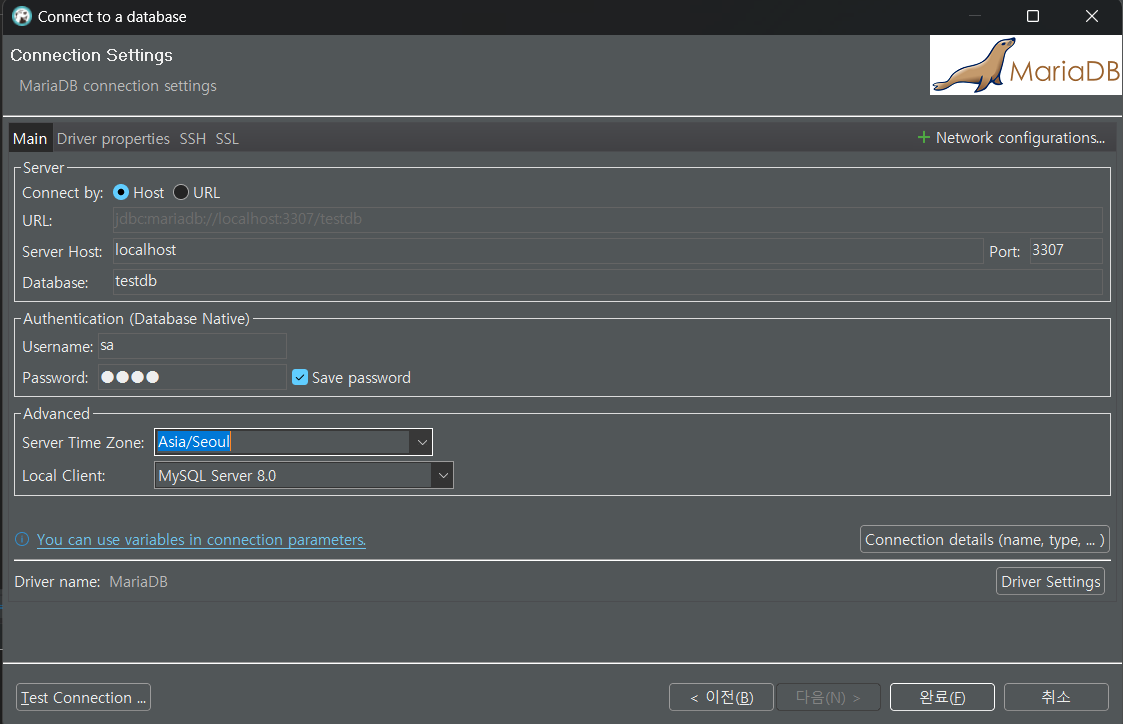
저는 먼저 MariaDB를 연결해보도록 하겠습니다.

다음과 같이 설정하는 창이 나옵니다.
자신이 만들었던 데이터베이스 설정에 맞게 작성합니다.
(저 같은 경우는 MySQL도 사용 중이기에 MariaDB Port를 3307로 설정해두어 변경했습니다.)
Server Time Zone도 Asia/Seoul로 설정하였고 설정이 완료되었다면 좌측 하단의 [Test Connection]을 클릭하여 연결에 대한 테스트를 진행해봅니다.
DBeaver는 JDBC로 MariaDB 연결을 진행하는데 MariaDB JDBC driver가 존재하지 않아 설치하라는 페이지가 뜹니다.
해당 페이지의 [Download]를 클릭하여 설치를 진행합니다.

이후 Connection test 탭에서 Connected라는 말과 함께 연결이 완료되었다는 점을 안내해줍니다.

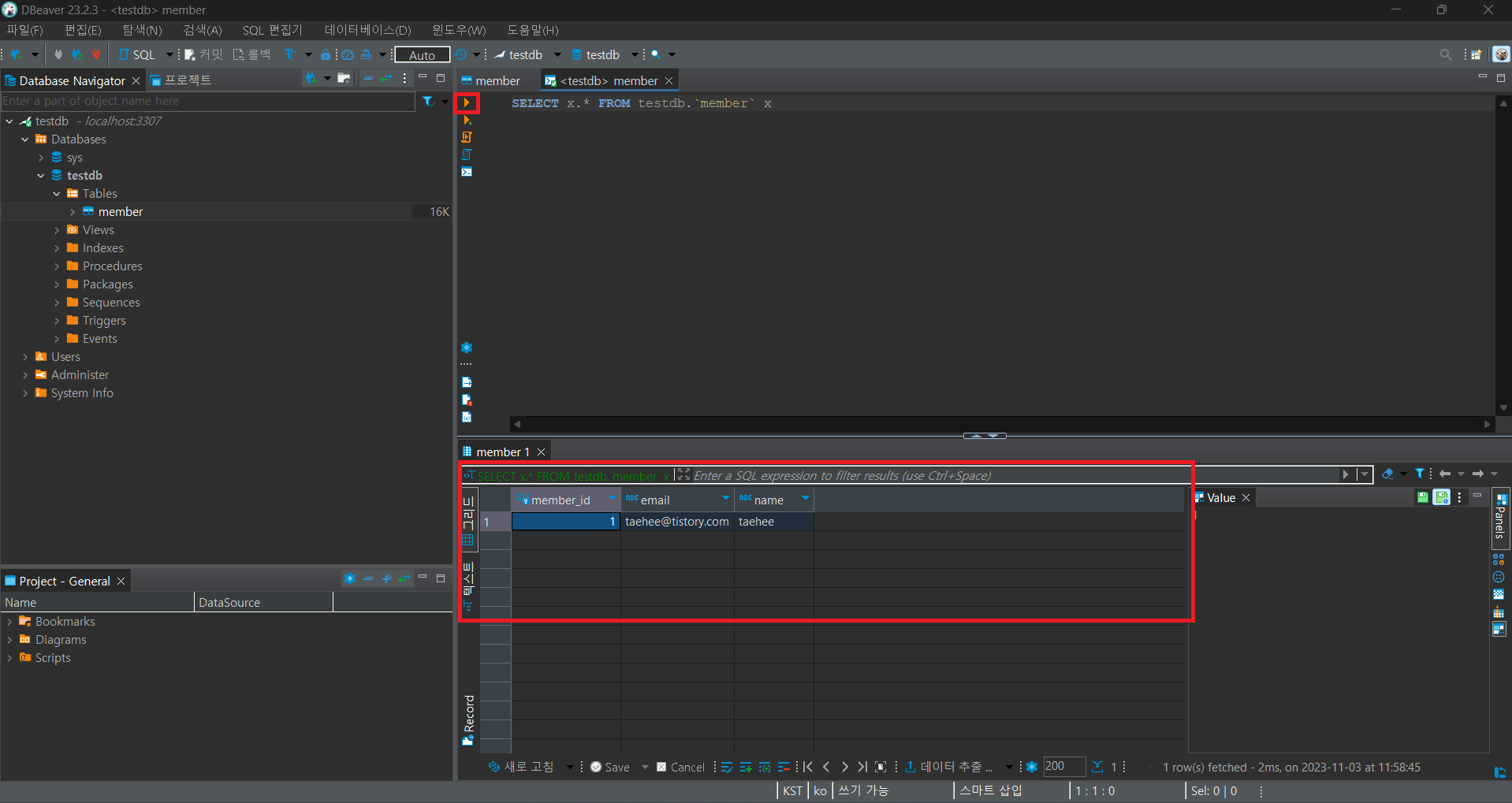
연결이 완료된 후 확인해보면 MariaDB 데이터베이스에 연결되었고 이전에 주입했던 데이터를 확인할 수 있음을 확인할 수 있습니다.

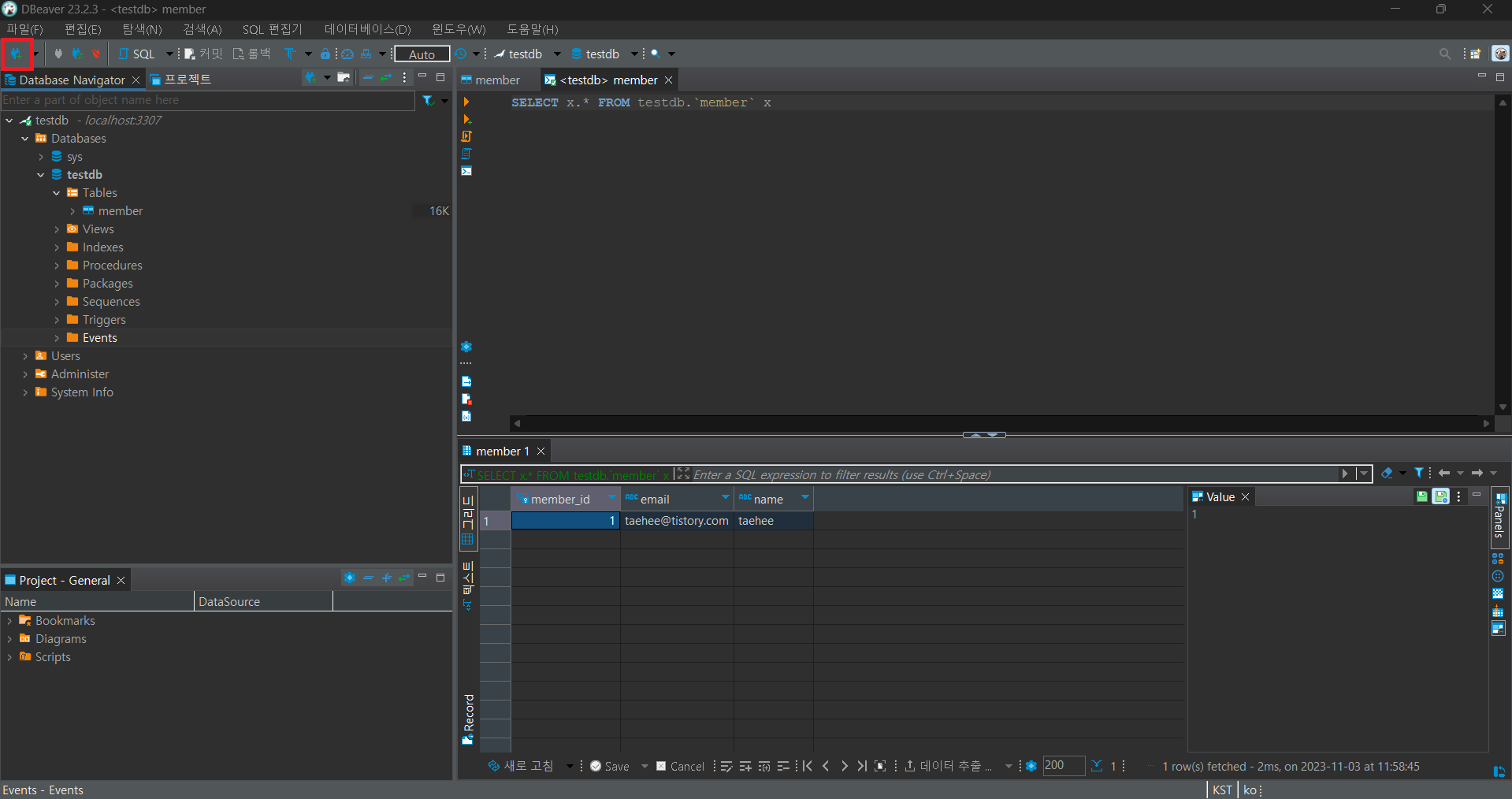
만약 쿼리문을 실행하고 싶다면 빨간 네모칸 부분을 더블 클릭하시면 됩니다.

더블 클릭을 통해 나온 탭에서 좌측의 실행 버튼을 누르시면 아래에 결과물을 확인 할 수 있습니다.
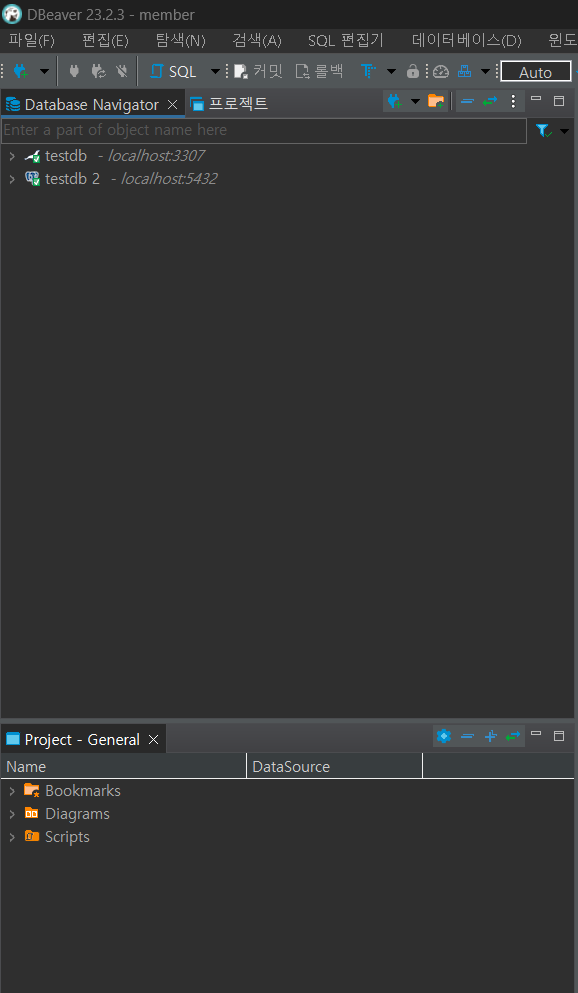
이후 추가를 원하는 DB가 있으면 좌측 상단의 [새 데이터베이스 연결] 버튼을 클릭하여 위와 동일하게 설정을 하시면 됩니다.
제 경우에는 MariaDB와 PostgreSQL을 연결했습니다.
추가 정보
아래의 주소를 통해 DBeaver에 대한 더 많은 정보를 확인하실 수 있습니다.
DBeaver 소스 코드 확인하기
https://github.com/dbeaver/dbeaver
GitHub - dbeaver/dbeaver: Free universal database tool and SQL client
Free universal database tool and SQL client. Contribute to dbeaver/dbeaver development by creating an account on GitHub.
github.com
DBeaver 위키
https://github.com/dbeaver/dbeaver/wiki
Home
Free universal database tool and SQL client. Contribute to dbeaver/dbeaver development by creating an account on GitHub.
github.com
Reference
'DB' 카테고리의 다른 글
| Materialized View란? (0) | 2025.02.06 |
|---|---|
| [MariaDB] ELT (랜덤한 값 넣을 때, 사용한 함수) (0) | 2025.01.17 |
| TDE란? (0) | 2024.11.26 |
목차
개요
Spring 내에서 다중 DB를 사용하고 싶으면 다중 DB 설정을 진행해야한다고 합니다. 기존에 사용하듯이 application.yml과 같은 설정 파일에 하나의 DB만 설정하면 Spring Boot에서 자동 구성(Auto Configuration)을 통해 문제 없이 사용 할 수 있었지만 다중 DB 설정에는 자동 구성이 되지 않기 때문에 설정 파일 값을 읽어와 연동 할 DB 수 만큼 Datasource를 수동 설정해야한다고 합니다.
application.yml 설정
아래와 같이 application.yml을 설정하였습니다.
second-datasource는 본인 원하는대로 이름을 붙이면 됩니다. (예를 들면, second.datasource)
Datasource 설정에서 주입해줄 것이기 때문에 상관없습니다.
spring:
# primary datasource
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/testdb
username: sa
password: 1234
# second datasource
second-datasource:
driver-class-name: org.mariadb.jdbc.Driver
url: jdbc:mariadb://localhost:3307/testdb
username: sa
password: 1234
jpa:
show-sql: true
hibernate:
ddl-auto: update
properties:
hibernate:
format_sql: true
Datasource 설정
application.yml 설정을 마치면 Datasource 설정을 진행합니다. 2개의 Datasource를 만드려고 합니다. 첫 번째 Datasource는 PrimaryDatasource, 두 번째 Datasource는 SecondDatasource라고 부르도록 하겠습니다. 설정과 관련된 코드를 살펴보겠습니다. (주석으로 간단한 설명을 첨부하겠습니다.)
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories(
basePackages = "com.multipleDB.repositoryConfig.primary", // 첫번째 Repository가 있는 패키지 경로
entityManagerFactoryRef = "primaryEntityManagerFactory", // EntityManager 이름
transactionManagerRef = "primaryTransactionManager" // 트랜잭션 매니저 이름
)
public class PrimaryDatasourceConfig {
@Bean
@Primary
@ConfigurationProperties("spring.datasource") // application.yml에 작성된 첫 번째 DB 설정의 시작 부분
public DataSourceProperties primaryDatasourceProperties() {
return new DataSourceProperties();
}
@Bean
@Primary
@ConfigurationProperties("spring.datasource.configuration") // application.yml에 작성된 첫 번째 DB 설정의 시작 부분에 .configuration을 붙여준다.
public DataSource primaryDatasource() {
return primaryDatasourceProperties()
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
}
@Bean(name = "primaryEntityManagerFactory")
@Primary
public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(EntityManagerFactoryBuilder builder) {
DataSource dataSource = primaryDatasource();
return builder
.dataSource(dataSource)
.packages("com.multipleDB.member") // 스캔이 필요한 패키지 경로
.persistenceUnit("primaryEntityManager")
.build();
}
@Bean(name = "primaryTransactionManager")
@Primary
public PlatformTransactionManager primaryTransactionManager(final @Qualifier("primaryEntityManagerFactory") LocalContainerEntityManagerFactoryBean localContainerEntityManagerFactoryBean){
return new JpaTransactionManager(localContainerEntityManagerFactoryBean.getObject());
}
}
위와 같이 4개의 Bean을 만들어주면 된다고 합니다.
첫 번째 DB 설정에는 @Primary를 붙여야지만 그 이외의 DB 설정에서는 @Primary를 빼주어야 합니다. 맨 처음 코드에서 Class 이름은 'PrimaryDatasource'라고 짓는 실수를 했었습니다. 해당 실수의 결과로 아래의 에러 로그를 만났었습니다.

위 사진에 나와있는 로그대로 overriding을 허가해주는 방법으로 해결하려 했지만 여전히 아래의 에러 로그로 문제가 생겼었습니다.

확인해본 결과 Class 이름과 job 이름이 동일해서 발생한 오류라고하여 클래스 이름을 'PrimaryDatasourceConfig'로 변경하여 해결했습니다.
(또한 overriding을 허가해주던 설정을 삭제하였습니다.)
두 번째 Datasource도 동일한 방법으로 진행하면 됩니다.
두 번째 Datasource에 대한 코드는 테스트 과정에서 발생한 이슈를 해결한 코드와 함께 보여드리도록 하겠습니다.
테스트 진행
이슈 발생
설정을 완료한 후 무사히 진행되는지 확인하기 위해 간단한 Member 클래스와 관련 Controller, Service 클래스를 생성한 후, Postman을 통해 member가 잘 생성되는지 확인하려고 했습니다.
테스트를 진행하기 위해 생성된 데이터베이스 중 MariaDB 쪽은 member 테이블을 생성하지 않았기에 ddl-auto 설정에 따라 member 테이블 생성하는 쿼리가 아래 사진과 같이 발생하여야 하는데 아무런 쿼리가 발생하지 않았고 확인해본 결과 member 테이블을 생성되지 않았음을 확인하였습니다.

이슈의 원인
이슈의 원인은 jpa, hibernate 설정을 datasource에 넣어주지 않아서였습니다. 아래와 같은 코드를 datasource 설정 클래스에 추가해주어야 했습니다.
@RequiredArgsConstructor
...
public class SecondDataSourceConfig {
private final JpaProperties jpaProperties;
private final HibernateProperties hibernateProperties;
@Bean(name = "primaryEntityManagerFactory")
@Primary
public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(EntityManagerFactoryBuilder builder) {
Map<String, Object> properties = hibernateProperties.determineHibernateProperties(jpaProperties.getProperties(), new HibernateSettings());
DataSource dataSource = primaryDatasource();
return builder
.dataSource(dataSource)
.packages("com.multipleDB.member") // 스캔이 필요한 패키지 경로
.persistenceUnit("primaryEntityManager")
.properties(properties)
.build();
}
...
}
위와 같이 설정해주어야 application.yml에서 설정한 JPA, hibernate 설정 값들이 적용된다고 합니다. 또한 JPA의 Naming Strategy도 위와 같은 설정이 있어야 정상적으로 작동한다고 합니다.
Naming Strategy란?
원래 JPA의 기본 설정상으로는 변수명이 camelCase로 작성되어 있으면 DB의 테이블이나 필드 이름이 snake_case로 매칭되도록 합니다. camelCase를 SNAKE_CASE로 변경하는 등 변화를 줄 수 있는데 이러한 전략들을 JPA의 Naming Strategy라고 합니다. 조직 내부의 약속대로 설정하는 법을 알고 싶다면 아래의 블로그 글을 참조해주세요.
https://velog.io/@mumuni/Hibernate5-Naming-Strategy-%EA%B0%84%EB%8B%A8-%EC%A0%95%EB%A6%AC
https://velog.io/@devduhan/Spring%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8-JPA-Naming-%EC%A0%84%EB%9E%B5
이슈 해결 내용을 적용한 Datasource
앞선 이슈를 해결한 Datasource 코드를 공유드리도록 하겠습니다.
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories(
basePackages = "com.multipleDB.repositoryConfig.second",
entityManagerFactoryRef = "secondEntityManagerFactory",
transactionManagerRef = "secondTransactionManager"
)
@RequiredArgsConstructor
public class SecondDatasourceConfig {
// jpa, hibernate property 값 주입하기 위해
private final JpaProperties jpaProperties;
private final HibernateProperties hibernateProperties;
@Bean
@ConfigurationProperties("spring.second-datasource")
public DataSourceProperties secondDatasourceProperties() {
return new DataSourceProperties();
}
@Bean
@ConfigurationProperties("spring.second-datasource.configuration")
public DataSource secondDatasource() {
return secondDatasourceProperties()
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
}
@Bean(name = "secondEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean secondEntityManagerFactory(EntityManagerFactoryBuilder builder) {
DataSource dataSource = secondDatasource();
Map<String, Object> properties = hibernateProperties.determineHibernateProperties(jpaProperties.getProperties(), new HibernateSettings());
return builder
.dataSource(dataSource)
.packages("com.multipleDB.member")
.persistenceUnit("secondEntityManager")
.properties(properties)
.build();
}
@Bean(name = "secondTransactionManager")
public PlatformTransactionManager secondTransactionManager(final @Qualifier("secondEntityManagerFactory") LocalContainerEntityManagerFactoryBean localContainerEntityManagerFactoryBean) {
return new JpaTransactionManager(localContainerEntityManagerFactoryBean.getObject());
}
}
위와 같이 설정을 완료한 뒤 다시 코드를 실행하니 테이블 생성 쿼리문도 무사히 출력되었고 확인해본 결과 member 테이블이 잘 생성되었음을 확인할 수 있었습니다.

또한 Postman으로 요청을 보낸 결과 무사히 데이터가 들어갔음을 확인 할 수 있었습니다.

Reference
https://velog.io/@lehdqlsl/SpringBoot-JPA-Multiple-Databases-%EC%84%A4%EC%A0%95
목차
JPA와 PostgreSQL 연동
라이브러리 설치
MySQL을 연동할 때와 같이 JPA 라이브러리 설치와 PostgreSQL 라이브러리 설치를 진행합니다.
build.gradle에 아래의 코드를 추가합니다.
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.postgresql:postgresql:42.6.0'
application.yml 설정
MySQL을 연동할 때와 같이 application.yml에 DB 접속 정보 및 JPA 설정을 입력해야 합니다.
spring:
datasource:
url: jdbc:postgresql://localhost:5432/<DB명>
username: <PostgreSQL 계정명>
password: <비밀번호>
driver-class-name: org.postgresql.Driver
jpa:
show-sql: true
database: postgresql
hibernate:
ddl-auto: update
위 두 설정을 마치면 MySQL과 같은 방식으로 사용하면 된다고 합니다.
한 가지 주의 할 점은 PostgreSQL에서 Table명으로 "user"를 사용하면 에러가 발생한다고 합니다.
실습
앞서 알아본 내용을 적용하여 간단한 테이블을 생성하고 연동해보려고합니다.
프로젝트 생성
start.spring.io에 방문하여 다음과 같이 프로젝트를 생성하도록 하였습니다.
Dependencies에서 사용하고자하는 라이브러리들을 미리 선택할 수 있는데 PostgreSQL Driver도 있기에 추가하였습니다.

데이터베이스 생성
Spring에 연결해줄 데이터베이스를 생성합니다.
PostgreSQL의 SQL Shell을 실행해줍니다.

접속하면 Server부터 Username까지 엔터로 넘겨줍니다.
암호는 PostgreSQL 설치 때 생성했던 root 계정의 암호를입력해주면 됩니다.

DB 계정 생성 및 권한 부여하기를 진행합니다.
//계정 생성
CREATE ROLE [USER] WITH LOGIN PASSWORD '[PASSWORD]';
//CREATEDB 권한 부여
ALTER USER [USER] WITH CREATEDB;
//SUPERUSER 권한 부여
ALTER USER [USER] WITH SUPERUSER;
//CREATEROLE 권한 부여
ALTER USER [USER] WITH CREATEROLE;
저는 sa 라는 이름으로 계정을 생성했습니다. 비밀번호는 1234로 설정하였습니다.

DB를 생성할 수 있는 권한 또한 부여했습니다.

\du 명령어를 통해 계정과 역할이 잘 생성되었는 확인합니다.

새로운 데이터 베이스를 생성합니다.
소유자는 앞서 만든 sa로 데이터 베이스 이름은 TESTDB로 하겠습니다.

\l (소문자 L 입니다)을 통해 데이터베이스 생성을 확인합니다.

아래와 같은 명령어를 통해 sa 유저 이름으로 TESTDB에 접속할 수 있습니다.
(\c [DB Name] [Connection User])

application.yml 설정
아래와 같이 application.yml 설정을 진행합니다.
spring:
datasource:
url: jdbc:postgresql://localhost:5432/testdb
username: sa
password: 1234
driver-class-name: org.postgresql.Driver
jpa:
show-sql: true
database: postgresql
hibernate:
ddl-auto: update
Member 생성해보기
간단하게 Member 객체를 생성하는 코드를 만들고 실행합니다.
DB 내에서 테이블을 생성한 적이 없기 때문에 테이블이 생성되는 SQL 문이 실행되었음을 확인하실 수 있습니다.

\d 명령어를 통해 확인해보시면 기존에는 테이블이 없기 때문에 '관련 릴레이션 찾을 수 없음.'이었다가 테이블 생성이 완료되었기 때문 테이블 목록을 확인할 수 있습니다.


아래와 같이 PostMan을 이용하여 Post 요청을 보내보았습니다.

다음과 같이 잘 생성되었음을 확인할 수 있습니다.

Reference
'Spring' 카테고리의 다른 글
| Spring 청크 통신을 편리하게 쓰게 해주는 ResponseBodyEmitter 써보기 (0) | 2025.01.09 |
|---|
목차
PostgreSQL 설치하기
아래의 주소에 방문합니다.
https://www.postgresql.org/download/windows/
1. 페이지 접속 후 Download the installer 링크를 클릭합니다.

2. Windows x86-64에서 원하는 PostgreSQL Version을 선택하여 설치 버튼을 클릭합니다.

3. [다운로드] 폴더에 가시면 설치 파일이 생성되었음을 확인하실 수 있습니다. 해당 파일을 실행하여 설치를 진행합니다.

4. [Next] 버튼을 클릭하여 설치를 시작합니다.

5. 설치 경로를 지정합니다. (저는 기본 설정 값으로 진행했습니다.)

6. 모두 설치합니다.

7. Data Directory를 지정합니다. (저는 기본 경로로 설정하였습니다.)

8. Root 사용자와 슈퍼 사용자의 비밀번호를 설정합니다. 잃어버리시면 안됩니다!!

9. 포트 번호를 지정합니다. (저는 기본 포트인 5432로 설정했습니다.)

10. Locale을 [Korean, Korea]로 선택합니다.

11. 2번 정도의 [Next] 버튼을 더 클릭하시면 다음과 같이 설치가 진행됩니다.

12. 설치가 완료되면 체크 박스를 해제하고 [Finish] 버튼을 누릅니다. 설치가 끝났습니다!!

'DB > PostgreSQL' 카테고리의 다른 글
| PostgreSQL이란? (내부 구조와 장단점 및 MySQL과의 차이) (1) | 2023.10.23 |
|---|
목차
PostgreSQL이란?
PostgreSQL은 오픈소스 객체-관계형 데이터베이스 시스템(ORDBMS)으로, Enterprise급 DBMS의 기능과 차세대 DBMS에서나 볼 수 있을 법한 기능들을 제공합니다. 약 20여년의 오랜 역사를 갖는 PostgreSQL은 다른 관계형 데이터베이스 시스템과 달리 연산자, 복합 자료형, 집계 함수, 자료형 변환자, 확장 기능 등 다양한 데이터베이스 객체를 사용자가 임의로 만들 수 있는 기능을 제공함으로써 마치 새로운 하나의 프로그래밍 언어처럼 무한한 기능을 손쉽게 구현할 수 있습니다.
PostgreSQL 내부 구조
postgreSQL의 프로세스 구조를 간단히 살펴보면 다음과 같습니다.

클라이언트는 (1)인터페이스 라이브러리(libpg, JDBC, ODBC 등의 다양한 인터페이스)를 통해 서버와의 연결을 요청하면, (2)Postmaster 프로세스가 서버와의 연결을 중계합니다. 이후 (3)클라이언트는 할당된 서버와의 연결을 통해 질의를 수행합니다. Shared Memory를 이용하여 GC와 같은 작업을 통해 MVCC를 관리합니다.
서버 내부의 질의 수행 과정을 간단히 살펴보면 다음과 같습니다.

클라이언트로부터 질의 요청이 들어오면 (1)구문 분석 과정을 통해 Parse Tree를 생성하고 (2)의미 분석 과정을 통해 새로운 트랜잭션을 시작하고 Query Tree를 생성합니다.
이후 (3)서버에 정의된 Rule에 따라 Query Tree가 재생성되고 (4)실행 가능한 여러 수행 계획 중 가장 최적화된 Plan Tree를 생성합니다. (5) 서버는 이를 수행하여 요청된 질의에 대한 결과를 클라이언트로 전달하게 됩니다.
서버의 쿼리 수행 과정에서는 데이터베이스 내부의 시스템 카탈로그가 많이 사용되는데, 사용자가 함수나 데이터 타입은 물론 인덱스 접근 방식 및 RULE 등을 시스템 카탈로그에 직접 정의할 수도 있습니다. 따라서 PostegreSQL에서는 이것이 기능을 새로 추가하거나 확장하는데 있어 중요한 포인트로 활용됩니다.
이러한 작업 방식이 방대한 데이터에 복잡한 쿼리에서는 높은 성능을 보이지만 작은 데이터에 간단한 쿼리에는 오히려 약점을 보이는 이유인 것으로 보입니다.
데이터가 저장되는 파일들은 여러개의 페이지들로 구성되며, 하나의 페이지는 확장 가능한 slotted page 구조를 가집니다.
- 데이터 페이지 구조

- 인덱스 페이지 구조

PostgreSQL 장단점 및 MySQL과의 차이점
PostgreSQL 장단점
| 장점 | 단점 |
| 함수, 데이터 유형, 언어 등을 추가할 수 있는 확장성이 높음 | 단순한 CRUD, 작은 데이터 셋에서는 MySQL보다 낮은 성능을 제공하는 경우가 있음 |
| 구조화되지 않은 데이터 유형 지원(예: 오디오, 동영상, 이미지) | 독창적인 자료형과 문법 때문에 러닝 커브가 있음 |
| 교착 상태가 거의 발생하지 않고 동시 처리가 가능하며 트랜잭션 속도가 빠른 MVCC | 독창적인 자료형 및 문법으로 인해 다른 DB로 migration이 쉽지 않 |
| 고가용성 및 서버 장애 복구 | |
| 데이터 암호화, SSL 인증서, 고급 인증 방법과 같은 보안 기능 | |
| 활발한 오픈소스 커뮤니티가 지속적으로 솔루션을 개선하고 업데이트 |
MySQL과의 차이점
MySQL8.0 업데이트를 기준으로 PostgreSQL과의 차이점이 많이 사라졌다고 합니다. 그럼에도 존재하는 MySQL과의 차이점을 소개드립니다.
1. MVCC 성능이 PostgreSQL에서 더 좋다.
2. PostgreSQL은 고급 인덱싱 기법들을 제공한다. (GIN, GiST 등)
결론
PostgreSQL에 대해 간단히 알아보았습니다. 공부하다보니 Java의 GC와 같은 Vaccum이 있고 저장하는 페이지 자료형에 대한 내용도 있고 공부할 것이 많더군요. 찬찬히 공부해보며 정리해보려고합니다.
그리고 장단점과 차이점등에 대해서는 구글링을 통해 얻은 지식을 정리했지만 실무에서 사용해보며 몸으로 체감하는 차이점을 적을 수 있는 날이 왔으면 좋겠습니다.
Reference
https://d2.naver.com/helloworld/227936
https://mangkyu.tistory.com/71
https://mystory-blog.vercel.app/blog/mysql-to-postgres/mysql-versus-postgres
https://cloud.google.com/learn/postgresql-vs-sql?hl=ko
https://codecamp.tistory.com/2
https://gksdudrb922.tistory.com/245
'DB > PostgreSQL' 카테고리의 다른 글
| 윈도우에 PostgreSQL 설치하기 (0) | 2023.10.24 |
|---|
목차
개요
Spring Documentation에서 WebSocket API를 공부한 뒤 다음 단계는 SockJS 였습니다. SockJS를 간단히 공부해보았는데요. 공부해봤을 때, 'SockJS가 필요없는건가?'라는 생각이 들어 블로그 글을 정리해봤습니다. 만약 SockJS에 대해 자세히 알아보고 싶으신 분은 아래의 블로그를 참조해주시길 부탁드립니다.
[Spring Boot] WebSocket과 채팅 (2) - SockJS
[Spring Boot] WebSocket과 채팅 (1) 일전에 WebSocket(웹소켓)과 SockJS를 사용해 Spring 프레임워크 환경에서 간단한 하나의 채팅방을 구현해본 적이 있다. [Spring MVC] Web Socket(웹 소켓)과 Chatting(채팅) 기존 공
dev-gorany.tistory.com
SockJS란?
SockJS는 애플리케이션이 WebSocket API를 사용할 때, 만약 브라우저가 WebSocket을 받아들이지 못하는 상태라면 애플리케이션 코드 변경 없이 런타임에서 대안을 실행하기 위한 것입니다.

위 그림에서 처럼 각 브라우저의 버전에 따라 WebSocket을 지원하지 않는 경우가 있습니다. 또한 Server, Client 중간에 위치한 Proxy가 Upgrade Header를 해석하지 못해 서버에 전달하지 못할 수 있습니다. 마지막으로 Server, Client 중간에 위치한 Proxy가 유휴 상태에서 도중에 Connection을 종료시킬 수도 있습니다.
이런 상황에 사용하는 것이 WebSocket Emulation입니다. WebSocket Emulation은 우선 WebSocketㅇ르 시도하고 실패할 경우 HTTP Streamin, Long Polling과 같은 HTTP 기반의 다른 기술로 전환해 다시 연결을 시도하는 것을 뜻합니다.
Spring을 사용하기에 SockJS를 사용합니다.
(Node.js는 Socket.io라는 것을 사용한다고 합니다. SockJS-node를 사용해도 될 것 같네요.)
필요없다고 생각하는 이유
브라우저 버전의 고도화
공부하다보니 SockJS를 사용해야하는가에 대한 의문이 들었습니다. SockJS를 사용하는 대표적인 이유가 WebSocket을 지원하지 않는 브라우저를 사용하는 경우이기 때문인데요. 대표적으로 IE 버전 10미만의 인터넷 익스플로러가 지원이 되지 않습니다. 하지만 마이크로소프트 공식 홈페이지에는 인터넷 익스플로러에 대한 지원이 2022년 6월 15일에 종료되었다고 하더군요. 또한 Firefox 인터넷도 자동 업데이트를 하도록 설정되어있다고 하기에 웬만한 브라우저는 다 지원되지 않을까라는 생각을 했습니다.

프록시 서버의 웹소켓 지원
두 번째로 SockJS를 사용해야하는 이유는 프록시 상황에서 웹소켓을 사용하기 어렵다는 이야기를 들었기 때문입니다. 하지만 찾아보니 Nginx의 경우에는 버전 1.3부터 WebSocket을 지원하며 WebSocket의 로드밸런싱을 수행할 수 있다고 합니다.
결론
SockJS에 대해 간단히 알아보고 필요없다고 생각한 이유에 대해서도 알아봤습니다. 혹시 최근에도 SockJS를 이용하여 작업하시는 분이 계시다면 어느 상황에서 사용되는지 알려주시면 대단히 감사드리겠습니다.
reference
https://docs.spring.io/spring-framework/reference/web/websocket/fallback.html
https://github.com/sockjs/sockjs-client/
https://dev-gorany.tistory.com/224
https://hyeon9mak.github.io/nginx-web-socket-proxy-configuration/
'Spring > 웹소켓' 카테고리의 다른 글
| WebSocket API를 사용해 채팅창 구현하기 (0) | 2023.10.10 |
|---|---|
| AJAX, HTTP Streaming, Long Polling 이란? (0) | 2023.09.22 |
| 웹소켓 공부를 시작하며 (0) | 2023.09.21 |